THIS ARTICLE IS UNDER HEAVY DEVELOPMENT!
Why do we need to think about scripting? Well, in an ORACLE-environment you normally do not deploy via JDBC oder ODBC. You want to take advantage of all those features which are not supported (yet) via any non-native driver.
Even if you don’t consider to do a deployment with help of ORACLE (I can not imagine such a scenario), you should be aware of a deployment to ORACLE without any help of third-part-tools.
Let’s have a look back in the not so far history: ORACLE introduced a CLI-tool called SQL*Plus. It is old but very stable. Behind the scenes (nearly) every tool uses SQL*Plus-features, even SQL*Developer resides on its basics on SQL*Plus and inherits most of its features.
So whenever you develop or deploy with SQL*Developer and/or SQL*Plus and you want to be sure to develop versatile scripts, you should read ahead.
Let’s have a look on how e.g. SQL*Plus works. SQL*Plus is (you máy not believe it) still used to deploy scripts and therefore objects. A reason, that SQL*Plus is still used may be the fact, that it is available in any environment and there is no other opportunity to develop scripts which are independant of SQL*Plus unless your deployments are not dependant on ORACLE. Of course you can write scripts to deploy objects via ODBC, but this will never give you the possibilities to benefit from a mature RDBMS as ORACLE is.
Avoid blank lines in scripts
If you prepare scripts to whether deploy a procedure or an DML-Statement like UPDATE to change rows in production you should consider blank lines to be potential enemies.
Why?
The SQL*Plus interpreter is a very simple thing, if you know, that the interpreter behaves different to certain keywords.
Example given:
If you type in a SELECT-statement in SQL*Plus and provide a blank line, the interpreter will go to initial state, meaning your multi-line-statement will be ignored and any additional line (which was supposed to be part of your statement) will be treated as an error.
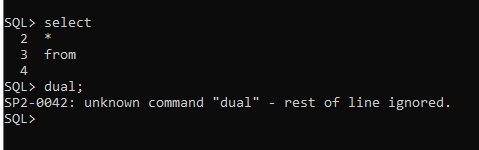
Now the annoying thing: this is only valid for certain statements, like INSERT, UPDATE, DELETE and SELECT.
If you plan to deploy objects with CREATE blank lines are allowed. Sometimes…
If you use DDL commands (CREATE, ALTER and DROP), behaviour is as usual: do not use blank lines in your statements (basically using DDL commands), it will fail.

But as soon as you try to deploy PL/SQL objects like procedures, functions, packages or objects, the interpreter changes its behaviour: it allows to use as many blank lines as you want, because your code is sent to the server after a slash /.
So blank lines in those commands do not hinder to deploy PL/SQL objects. But be aware to use the trailing slash /, otherwise this will lead to errors in upcoming commands.

Be aware of / and ; at the end of DDL/DML scripts
I had many colleagues not understanding the difference of ; and /.
All of us know, that in SQL*Plus (and SQL*Developer and so on) a SQL-Statement has to be terminated by a semicolon and will execute immediately.
Well, a SQL-Statement…
Consider four differerent approaches:
Script 1
update x set a = a + 10
nothing will happen, since you missed to provide the semicolon, upfollowing commands may lead to errors.
Script 2
update x set a = a + 10;yes, thats a good script. The DML-command is terminated by a semicolon and therefore will be executed immediately. SQL*Plus will afterwards be in „initial state“ to receive the following commands.
Script 3
update x set a = a + 10;
/this is a bad script, since the statement is terminated by a semicolon and therefore executes immediately. The additional slash (/) means: execute the last given statement again. This will lead to an increase of a by 20, but it was intended to increase by 10
Script 4
begin
update x set a = a + 10;
end;
/This is a good script, because it increases a by 10 for each time it is executed. The lasting slash (/) is responsible for executing the block. Without providing the slash upcoming commands may fail, since the interpreter is still in „PL/SQL“-mode.
Script 5
create or replace procedure test as
begin
update x set a = a + 10;
end;
/This is a good script as well. The script itself will do nothing, since it only deploys a procedure which needs to be called to change column a of table x.
Be aware of SQL*Plus environment (set *)
Again this is about SQL*Plus, which is commonly used to bring things to production.
Your might encounter scripts like
SQL> set define off
SQL> insert into customers (customer_name) values ('Marks & Spencers Ltd');
1 row created.
SQL> select customer_name from customers;
CUSTOMER_NAME
------------------------------
Marks & Spencers Ltd
This e.g. is used to disable the default & to be used for substitution variables. So far so good, it lets you deploy data without being bothered by substituting variables which are not meant to be variables.
But the SET command is valid for your whole SQL*Plus session. So if there are upcoming scripts dealing with &-variables, this may lead to unexpected behaviour like here:
SQL> select * from dual where dummy='&var';
no rows selected
This script was intended to ask the executor to provide a value for &VAR, but since DEFINE was set to OFF by a previous executed script, the & does no more work as a variable indicator and leads to annoying side-effects.
So the essence is:
If you change SQL*Plus-settings via SET you should always set them back to their default behaviour after your script execution.
How to script
Let’s have a look on the idea of a versatile way to script deployments for a set of ORACLE objects like tables, views, procedures and so on. The way you go highly depends on your deployment strategy (which is covered in #link# more precisely).
I am used to distinguish between „persistant“ objects and „non-persistant“ objects. Persistant objects carry valuable information, in the very end your precious stored data. Whereas „non-persistant“ objects can be replaced without any data loss.
A persistant object is for sure a table, since it contains your data and needs survey. A view is „non-persistant“, since its replacement will not lead to a data leakage. This is valid for functions, procedures, packages as well.
What about indexes or materialized views? One could state, that both depend on data which is stored in tables and therefore easily can be replaced without any data loss. Yes, I agree. But if your data exceeds a somewhat maximum, it may be painful, to rebuild those objects from scratch (I currently deal with tables having 1.120.000.000+ rows, where a recreation of an index or Mview may be very annoying ).
How to script table creation
The table is the most precious ORACLE object, since it stores your precious data. Writing a CREATE-TABLE-script to deploy it to production sounds easy, but let us keep some things in mind:
Beside the table there are some more objects, which highly depend on the table: INDEXES and CONSTRAINTS. Of course there are additional objects relying on a table like procedures, packages, functíons, views or materialized views. But as said before, they can easily by recreated, because they do not carry business data.
Indexes are on the one hand generated automatically (e.g. if you provide a primary key constraint) and sometimes need to be defined in addition. Constraints ensure the integrity of your data and always should be considered to be part of a table creation.
So how to deal with indexes and constraints:
Your create-table script itself is easy: Provide the column definition (and be aware of VARCHAR2(1 byte) or VARCHAR2(1 char). That’s it. That’s your very basic table without any indexes and constraints.
Add a primary key. The way you do this (either by classifying a single column or by adding a combined primary key, this does not matter).
Now add your additional contraints to the create-table script. Do not separate them from the creation of the table, they should be part of the same script, since a successful deployment of a table needs all consistency rules to be in place as well.
But: Keep them disabled!
Why: If you do a „fresh“ deployment (meaning you do not need to consider any changes to an already existing installation) your task is first to deploy the persistent objects, then eventually load needed initial data and afterwards enable all constraints (which can then be done by a single script). What is the benefit? You can be sure, that your „structural“ architecture has been deployed successfully and problems regarding the enabling of constraints do only depend on a data problem, but not on a structural problem. In regards to foreign keys you still need to fullfill the correct order of deployment.
To make a long story short:
- Deploy your persistant objects (here: tables)
- create all additional constraints (but disabled)
- load your initial data
- enable the constraints
If you encounter problems in Step 4 you surely know that these problems come from your data and you can decide whether to stop your deployment due to errors or to go on and fix data issues afterwards. This is much better than to deal with problems in regards to an „interrupted“ change of structural data, where you need to decide to either stop your deployment (because an initial table load failed, but not all structural changes went through) or go on (then having in mind, that some DDL-commands have not been executed, because of dataloading issues, which halted the creation of additional objects).
How to script view creation
Do not use SQL*Developers DDL as a basis of your deployment script
grants are part of this DDL, which may interfere with your overall security concept.