Regarding the question „what naming ORACLE Naming convention standard should I choose“ I once read an interesting answer:
„naming conventions are purely subjective. That your convention makes sense, and that you use your standard consistently, are both much more important than wich standard you choose“.
I totally agree to the latter, and if I follow these advises, the reason for bad naming convention can only be the result of not knowing the sense of conventions.
Naming conventions are boring, no one cares. But you should care! To establish quality measurements, easy navigation through complex environments, get an easy onboarding for new colleagues and finally automate things based on these conventions. E.g. imagine triggers being deployed automatically, or even views being generated automatically if all conventions are met (see <link>).
And as always: the earlier you find the value of good naming conventions the cheaper it is to code with conventions and the easier it will be to set up automatisms with code generators.
Inhalt
- 1 Main goal with naming conventions
- 2 Table names (naming conventions)
- 3 Column names (naming conventions)
- 4 Constraint names
- 5 View names
- 6 Trigger names
- 7 Sequence names
- 8 Exception names
- 9 Synonym names
- 10 Package, procedure and function names
- 11 Summary
Main goal with naming conventions
To convince you of establishing naming conventions, just think of there were no.
Think about new colleagues who are needed to get productive soon.
Think about reporting needs (you need to report on used tables and colums and other objects).
Of course these questions can be answered by querying the ORACLE dictionary, but let us add some semantic into objects and dependencies. I will try to explain as much as possible in this article, but the major outcome will be visible later (see <link>).
Main goal is to put semantic into object names.
Table names (naming conventions)
- Construct your table names with a top-down method starting with general information/categorization getting more and more precise, the longer the table name is
- Use three- or four-letter abbreviations, delimited by an underscore. Allow freestyle at the end of the table name, but neverever omit the starting abbreviations
- Name your tables in singular mode
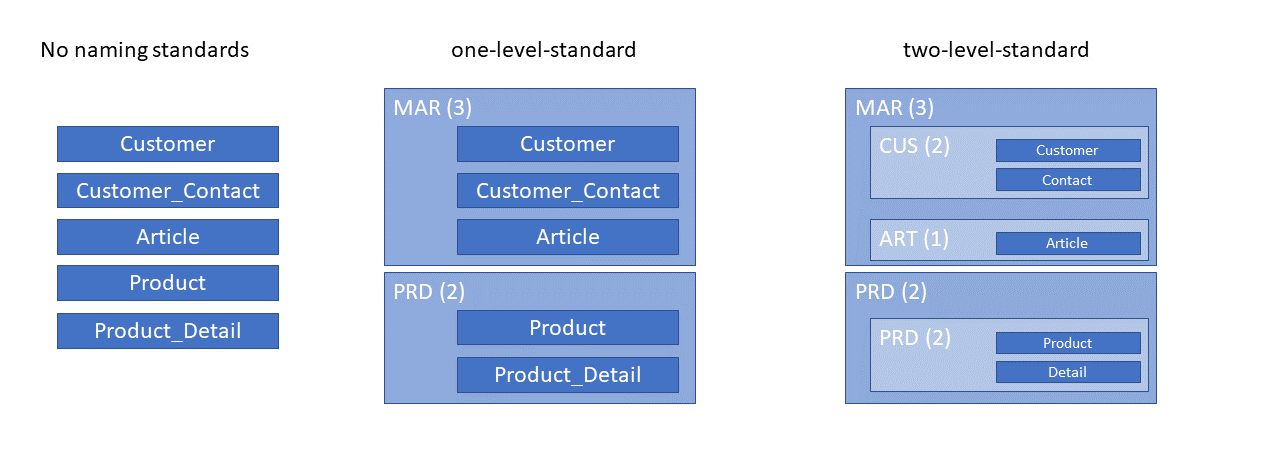
Whenever you create a table, your are pretty sure how to name it: „CUSTOMER“, „PRODUCT“, „ORDER“. In an environment, where you are confrontated with 100 and more tables (more than 1000 from my last project), this does no more fullfill all your needs. Your are not sure, whether your table is called „CUSTOMER“ or „CLIENT“ or your table is called „PRODUCT“ or „ITEM“. Maybe both exist but for different business units.
CUSTOMER
CUSTOMER_CONTACT
PRODUCT
PRODUCT_DETAIL
What do I expect an object name is telling me?
From my point of view I expect from reading the table name
- what is stored
- where does the data belong to (from a business point of view)
What I do not expect from an object name is
- is this data still valid (what the hell?? Why should I query outdated data??)
- is this data collected from other sources (if so, this is part of a so-called lineage query)
- are there any filters, which show only a subset of data (seems to be a task for a view)
- is this a big or small table (I can discover myself and it might vary)
- how is this table being used (e.g. only for INSERTING, but never for DELETING) (a question of processing, not of storage)
Therefore bad names are
2022_backup_customer, customer_from_marketing, customer_located_south, big_customer_tab, customer_insert_tab
But even these bad table names visualize different wishes to put semantic in such names.
Now lets put semantic in your table names by prefixing it with a three or four-letter code.Consider to assign your data to e.g. a business unit, a consuming or sourcing unit, a component, module or whatever you could assign your table to. In our case marketing deals with customers and production deals with products:
MAR_CUSTOMER
MAR_CUSTOMER_CONTACT
PRD_PRODUCT
PRD_PRODUCT_DETAIL
As you can see, some of this data is from or for marketing, other is from or for production.
Go ahead one level: marketing does not only deal with customers, but articles as well. Object names will soon become difficult to interpret by a computer, a valid report can only be done on the first three digits of the name.
Lets introduce a second level, with another 3-dot notation:
MAR_CUS_CUSTOMER
MAR_CUS_CONTACT
MAR_ART_ARTICLE
PRD_PRD_PRODUCT
PRD_PRD_DETAIL
At a first glance it may not look plausible why to „repeat“ the object in the second level notation (e.g. PRD_PRD, where the last PRD stands vor PRODUCT, so why to append PRODUCT explicitely? Same question goes to MAR_CUS? Why to repeat CUSTOMER?)
We want to use the table names to gather business information as much as possible. If I would not append the name PRODUCT to the already unique name of the table, it would be less informative. We then knew, that PRD_PRD is a table concerned with storage of products and belongs to production, but wie don’t know, what kind of product-related information is stored in this table.
It does not need much fantasy, to imagine an easy SQL-query to get a result like this. Watch the increase of additional information by only voting for naming conventions.
For a two-level-standard it looks like this
select substr(table_name, 1, 3), count() over (partition by substr(table_name, 1, 3),
substr(table_name,5,3), count() over (partition by substr(table_name, 1, 7),
substr(table_name,9) from user_tables;
This is only done by naming conventions, there is no need to establish any other repository with metadata.
Now imagine, if we find rules for foreign key naming to show dependencies and complexity within those components to highlight hotspots or nearly isolated modules or components. But here we are still on tables.
A word on tables reflecting relations
If it comes to naming tables which reflect a relation of tables of different „domains“, it gets somewhat difficult to decide, how to name this table.
Let’s take the image above with a two-level-standard. If a customer and its contacts are in a 1:many-relationship, we don’t need no relation table. If a contact is somewhat like a sales representative who can be active for more than one customer, we need an additional table. This table should definitely be named with the prefix MAR_CUS, since this table does not leave its „domain“.
Now assume you need to relate customers to articles. Since many customers can buy many arcticles, it is a n:m-realtionship and therefore needs a table. The initial prefix is self-explanatory, since the table connects data within the same domain „MAR“. And if I understand MAR_ART to be some kind of article directory I would not consider to put a relation table to that domain. Another aspect would be the likelyhood to join both domains for reporting issues. If I setup reporting for articles and customers, where is it more likely to use the relationship table? It is more likely, that an article exists without being sold than a customer in my customer-table who never bought an article. I think it is much more possible, that I have articles which have never been sold than customers, who never bought articles. Even more, sales are always related to customers but not mandatory to articles (e.g. because you sell services as well).
So, in this case all thoughts vote for a table in the namespace (domain) of customers, e.g. a table named MAR_CUS_CUS2ART.
Now imagine an article, which consists of many products like a table consists of different legs and different platforms. Again it is a many-to-many-relationship, legs can be combined with different platforms to form an article „table“. Do I assign such a table to namespace MAR? Surely not, since marketing is not interested in parts of an article. So my first table-prefix will be PRD, and what about the second prefix? It is nearly self-explanatory: Should I vote for PRD_ART? Is there any other table with this prefix? Should I open up a new domain PRD_ART? What is the semantic, when I have a table with MAR_ART and PRD_ART? Are there different article-informations in both domains?`No, there are not.
So you need a table in namespace (domain) PRD_PRD: PRD_PRD_PRD2ART.
What, if I did it wrong
Luckily nothing. Your decision to assign certain tables to certain namespaces will not have impact on automatism or any other aspect of a good ORACLE achitecture, as long as you name your tables according to your established standards. This ensures, that your tables „stay on the screen“. When we go on and define „ingoing and outgoing“ foreign key constraints, the directions of these „pointers“ may be not self-explanatory, but still explainable.
A word on „general“ components
You might identify needs for „general“ components like
- Backup-Tables
Tables need backup before manipulation of live-data is done - Logging-Tables
Tables where you log changes of data (e.g. security and monitoring needs) - Monitoring-Tables
Any information which does not need to be kept long-term, e.g. debugging or usage information
Since these needs seem not to apply for single tables only but for an overall concept you should introduce an own domain/namespace.
E.g.:
- Don’t call a backup table MAR_CUS_CUSTOMER_backup_2023 but BCK_MAR_CUS_CUSTOMER_2023
- Don’t call a logging table MAR_CUS_CUSTOMER_LOG but LOG_MAR_CUS_CUSTOMER
- Don’t call a monitoring table MAR_CUS_CUSTOMER_MON but MON_MAR_CUS_CUSTOMER
Referencing the above query to ask for a main overview of all components will get you a first component
- LOG
- MON and
- BCK
with at least the referenced component MAR. If you want to be more precise you have to extend your query to examine the third 3-letter-expression for tablenames starting with LOG, MON or BCK.
Consider those tables to be part of automations:
- delete rows older than one year from tables starting with LOG
- delete rows from MON when debugging option is disabled
- set tables with BCK read only or move them to another tablespace or drop them when creation_date exceeds six month
Put general components at the beginning of an object_name to form a solely component, even if you introduce another prefix-level for naming tables. If you don’t care about this additional „level“ your will report an own component with the above SQL-Statement, but missing a detail-level (which might be not relevant).
In regards to following automation, where you want to create triggers for logging or monitoring, this advice makes it much more easy to implement such automations.
Just imagine a developer, who implements his own log-table. His name might interfere with the general logging mechanism you wanted to apply to the whole application.
If you put LOG as a prefix for all relevant tables where you want to do a standardized logging, you do not collide with the (maybe additional logging) needs of a single developer. A developer is easily not allowed to create objects out of his mayor namespace (he can create a table MAR_CUS_CUSTOMER_LOG, but is not allowed to create LOG_MAR_CUS_CUSTOMER). So even if his locally developed logging mechanism fails, the overall logging in the component LOG will succeed 😉
A word on schemes
If your schema interacts with objects from other schemes, naming of tables (and other object types) is important! Try to avoid names which are not unique all over the referenced schemes.
Why not? I can make them unique by putting the owner in front of the object name?
select <col> from <owner>.<table>;
No, you dont want to do that. You would violate a concept called „Ortstransparenz“ (maybe translated with „location transparency“ or „storage transparency“?). You don’t want to hard-code where an object resides within ORACLE.
So you would introduce synonyms, which are hiding the owner of an object. One idea is to name the synonym as the object in the corresponding scheme is called. But what, if my local schema has an object with the same name as in the corresponding scheme and I name the synonym the same? If a synonym has the same name as an object in your scheme, ORACLE will always prefer the local object and deny to use the synonym. Hm, so you would be forced to name the synonym e.g. with the owner_name as an prefix for the object name where the synonym points to. Not good, but a possibility. I would prefer to name objects unique across all affected schemes. There is really no reason, why a table CUSTOMER should reside in different schemes.
This note comes into play, when you want to be as flexible as possible and deploy your development to different schemes. This may be the reason, when you have only one database, but different schemes to deploy in (different versions of your development or different data sets) or you need to migrate your application, because your customer has its own thoughts on the schema-name to be used.
Forget about this excourse, if your application deals only with data in its „own“ schema. If not, consider to set up naming conventions to be sure to be unique across all referenced schemes.
If you are affected, you should consider this excourse to be of high priority and have a look at <link> where I describe all prerequisites to deploy a multi-scheme-application to a database.
This is a test notice, my friend
Column names (naming conventions)
Again, naming conventions are about semantics, but can come into play for all types of generators and automatisms you want to use (think of a trigger generator who decides how to build up a trigger based on presence of certain columns or column combinations, e.g. whenever you have a column called last_modified you want a trigger to be generated who maintains a history of all changes to a row in the table and so more).
But first let’s care about semantic, and then for automation:
Avoid the same name for columns in different tables…
First, try to avoid the same column name in different tables. You don’t want to have two columns called name in both tables product and customer. In fact, it is a product_name and a customer_name, so name the columns accordingly. „But I can derive its source from the table name, where the column belongs to? Why should I code this information in the column name itself?“ There are plenty of reasons, but let me give only one example. If you plan a report on sales acvtivities you will soon be confronted with many names (sales representative name, product name, customer name, month name, sales team name and a category name of the product). A lot of names in just one report. Beside the readability of the query (where you are forced to notate the tablename in front of the columns, because it would otherwise be ambigiously defined) you will have additional efforts in working with column aliases to give those columns back the semantic of all those names. So better start with unique names without deriving its source or semantic from the tablename the column belongs to.
…but use the same name for systemwide valid concepts
The same column names are allowed to be used throughout multiple tables only and only if the column name has the same semantic. This may be the case e.g. for a SYS_LAST_MODIFIED-column which is used in your application as a general modification marker for all of your tables. „But, in deed, it is again different semantic: once a product last modified date and on the other a customers last modification date. Why not go for the same advice as with the names?“ Well, first of all, SYS_LAST_MODIFIED is not an attribute of a product or customer, but technically spoken an attribute of a whole row (when this row was inserted or updated). It is pretty seldom to display such information in any business type report and works „behind the scenes“. The prefix SYS I used may be be an additional indicator to understand, that those columns are somewhat systemwide used and follow the same ruleset over the whole application (here: logging, when the last change to a row of a table was made).
Avoid coding primitive datatypes or constraints in column names…
There is no need to call a column customer_name_v50 to indicate the columns datatype of varchar2(50). This is easy to find out by querying ORACLEs data dictionary. This goes for constraints as well: why should you code a column customer_name_nn to signal, that this is a not null column? This is not the goal of column_names but constraint names! You will quick identify problems, if you want to apply a uniqueness indicator in at least two columns of the same table. Using a postfix _UK in the column name will no more indicate, whether the combination of two columns need to be unique or each column on its own. Then the latest you have to query ORACLE to ask for the exact definiton of this uniqueness.
…but go for domains
Try to identify domains for your values. E.g. consider three typically used string-sizes for alphanumeric columns like SHORT for 20 characters, MEDIUM for 50 and LONG for 200 characters. Or introduce a domain DESC (for decription) which always needs to be implemented as VARCHAR2(4000).
Do not hesitate to introduce different domains for the same datatype. E.g. you need to store a date value in a numeric representation in more than one column, then you go for domains called DOM (Day of month) and MOY (month of year), both are defined as number(2) for value the ranges 1-31 and 1-12.
Why should I? First, both examples make it easy to migrate domains in an automated manner: If business decides to extend the domain SHORT from 20 characters to 25, it is easy to identify the affected columns (with a combination of (SHORT must be at the end of the column_name AND datatype must be varchar2(20)). Even if you introduced another domain SHORT for numerical values, those columns would not be affected by the migration, because their datatype is not varchar2(20). The same goes to DOM and MOY: Whenever you want to store the months name instead of its numeric representation you can easily migrate without affecting column of domain DOM.
Second, column datatypes in ORACLE are very basic: E.g. there is no column datatype POSITIVE to store only positive numbers. As you see, you might want to introduce a domain NUMPOS to be used only for positive numbers. Now we have three domains DOM (day of month), MOY (month of year) and NUMPOS (positive numbers) which make it easy to apply additional constraints on columns based on these domains. Your domain states e.g., that a day of month must be between 1 and 31 and a value of domain NUMPOS must be >=0. By using these domains as part of the column names it is easy to automatically identify the relevant columns and to trigger the automatic creation of check constraints on these columns, where the check constraint condition is derived from the used domain.

More ideas on domains:
- RATE (rate) (e.g. has a maximum of 2-digit decimal-place
- PCT (percentage) (can be between 0 and 100, maybe even negative)
- FREQ (frequency) (domain of values like „weekly“, „monthly“, „every week day“, every working day“ and so on)
- CODE (business code) (any code for a business term like country codes, airport codes or currency codes)
- FLAG (flag) (domain of values „Y“ and „N“ or „X“ and empty)
- WDAY (week day) (domain of 1-7)
Just to give you an idea, where this concept may become very mighty: If you manage to assign every column to a domain, you can even use this assignment e.g. to map the domain to a java datatype which is then used to create code sceletons with mappings to ORACLE columns. Or the other way round: You are confronted with use of java datatypes which are not that easily mapped to ORACLE datatypes. Construct a domain with a check constraint to be conform with the use of a certain datatypes in Java. Or consider to connect a domain to certain error-codes which are then used in your application („a weekday must be in the range from 1 to 7“ or else).
If you reach for the sky, you could even argue: If I already need to assign a domain to each column name, I don’t need to deal with the datatype, the column is based on. The column itself inherits its datatype from the domain it is assigned to. I could use another descriptive language to define my tables and columns and become more versatile and less prone to errors while defining table structures.
Domains and business codes
Hm, regarding the idea of a domain CODE: isn’t a domain FREQ a business code as well, since the set of values for FREQ depends on the field I am using this domain in (e.g. in a hospital the FREQ may be minutly, hourly and daily to watch after a patient or apply medicine, whereas FREQ in business of finance may be the frequency we are going to report to investors (daily, monthly, yearly)?
The benefit of investing in thoughts about domains is surely migrations aspects (I want to extend a certain domain throughout my application and I want to do it with as less analyse effort as possible) and a more restrictive ruleset than what is already inherited from the used datatype for the column (FLAG maybe VARCHAR2(1), but I want to be even more precise and set up a rule FLAG to be only „Y“ and „N“).
OK, we understand, with defining domains and its rules it is easily possible to derive check constraints for the chosen domain and apply those check constraints to columns which use this domain. Got it.
And what about CODE? The above is valid for CODE as well? An airport code is a list of valid values, right? And can be defined as a domain, right?
Well, it depends…
1. A domain is a very static rule which is not likely to change over time. E.g. domain FLAG (if understood as a corresponding checkbox in any user interface) is unlikely to change. It is hard to imagine, that the list of values will be extented by a third value „PERHAPS“. This applies for WDAY (weekday) as well and for PCT (percentage) and RATE dito.
2. A domain does not need foreign keys to get access to additional attributes (like translations to different languages) or to check, whether a value is allowed to be used or not. A Y/N-flag is a flag carrying no additional information, it is some kind of atomic.
This being said, let’s now evaluate the CODEs examples: Business codes are more volatile, they are created and they vanish, when they are no more valid (like airports do, currencies do and even countries do). Usually business codes carry additional attributes (e.g. a translation to different languages) you need access to and their value range can quick become larger than a CHECK-Constraint is able to validate. E.g. there are more than 35.000 airport codes around the world, you can’t construct a CHECK-Constraint to evaluate against 35.000 distinct values (at least not in ORACLE). So this is, where foreign key constraints (or triggers) come into play to decide, whether a value in those columns is valid or not.
Now have a look on this hybrid domain WDAY (weekday). On the one hand, this is a set of values 1-7, not more not less. Easily defined via a domain and checked with a check constraint. No need for foreign keys to a list of valid values, since those values are unlikely to be extended in the future. But: A weekday carries additional information you might need. Is it a working day? What is the name of the day? How do those weeksdays translate to different languages?
Remember the goal, we want to put semantic to column names to help us understanding the use of a column, where ORACLEs dictionary can not. And we want this information either coded in the column name to be used for automating purposes (like deriving check constraints for a given domain) or attached to the domain to reflect, that those codes are volatile or a huge amount of possible values which need other techniques to be evaluated than by a check constraint..
In case of a weekday I would not consider this column to be a foreign key to a table containing seven weekdays only to enforce integrity. If you would go this way, you would introduce many tables with not much rows in it like a YESNO-table, a MOY-table and so on.
I suggested to label a column name with a postfix to get the used domain out of the column name to automate, prepare to migrate and overall assure certain quality measurements. Let’s consider an optional attribute to a domain definition to reflect, that the column contains values, which are somewhat volatile and therefore might need 1. a foreign key and/or 2. no check constraint or not only a check constraint but a trigger?
Let’s look, how this can evolve:
First idea: columns containing a weekday
- day_of_trade number(1)
- service_done_on number(1)
We discussed that this information is not enough neither to establish a more precise domain (with help of a check constraint) nor to evaluate for used business codes to derive the name of the weekday 1-7. Even more, ORACLE could give no support to generate a unique check constraint all over those columns nor report on columns which containt a weekday. Go ahead, add the semantic, add a domain:
- day_of_trade_wday number(1)
- service_done_on_wday number(1)
I referenced a domain and now can automate generation of check constraints with help of my domain-table which is a two-column-table containing the domain_name and the check rule:
WDAY (check <column_name> between 1 and 7)
But WDAY is not only a domain but a business code as well, since it carries more attributes (day name as text at least, maybe even a flag, whether this is a working day or not and so on) or the list of values is too large to be checked by a check constraint?
You can store this information in your domain table as optional attributes beside the check constraint rule. Put the source-table and source-column to your domain table to either generate a trigger to evaluate against a large set of values (e.g. airport codes) or even generate a foreign key constraint (this is not what I would suggest, since the name of the column does not reflect dependencies to other tables, which might be irritating).

Of course, to use this naming concepts for automation purposes has certain impact: You are forced to use domain abbreviations in all column names.
If you put additional business code information to a domain, this implies that a domain can rely on only one business code. E.g. an airport domain AIRP (which is an airport IATA-Code as a 3-digit-abbreviation) is based on a datatype varchar2(3) and the business code can be derived from table AIRPORT_CODES from column AIRP_CODE (this is coded in your domain-table). If you want to add additional (e.g. military) airports, you need either to add them to your airport table (which was originaly intended to only store civil airports) or you have to introduce a new domain MAIRP for military airports.
The benefits of those rules may not be foreseeable yet, so if you are still not convinced have a look in <automations to ensure data quality, readability and maintainability>. And please rethink, that all this said does not mean, we use dynamic SQL in our application. We will not! The introduced metadata (which is one domain-table yet) does only enable us to generate standardized static code with less quality assurance efforts, less development efforts and leads to maintainable code where you concentrate on implementing business needs and get rid of standard implementations, which easily can be automated by putting semantic into column names.
Domains and column naming conventions are a valuable concept to apply automatisms to ensure data quality and integrity.
A word on foreign keys and business codes
One could state „all this discussion to business codes can be killed by using a foreign key to a business code table as the 3NF-idea and relational databases are made for.“ To go for 3NF you would need many code-tables, each containing only a few rows like gender-codes, direction-codes (east, west, north and south), yes-no-codes, currency-codes, country-codes, airport-codes, zip-codes, language-codes, bank-codes and many many additional dozens. This soon becomes a overwhelming amount of tables. „But your suggestions introduces the same amount of additional tables?“. No, it does not, the overall concept decides whether I introduce a gender-code-table or a yesno-code-table or I go for the check constraint only ( I even could combine both and let ORACLE generate a trigger to check whether a column gets a value assigned which is in my gender table)). I am much more flexible dealing with business codes without a foreign key to any code-table, than with foreign keys. The danger of inconsistency is given, no question asked, but it is very limited and can be crosschecked with automation scripts.
„OK, i decide to put all those codes into one business-code-table and reference this only table by a foreign key from all code-columns“. Good idea, but: you need to introduce an artificial primary key, since a code can exist more than one time (e.g. „F“ for „female“ and „F“ for „front“), so you would certainly generate a number and store 27 in a customer_gender_GENDER-column and you would store 45 in a column mounting_position_SURFACE. You loose information (F in these columns was still a readable code before) which needs to be regained by additional joins in case of basic reporting or any other questions regarding female customers. And even worse: If you need to disable the primary key of your CODE-table you need to disable all foreign keys in advance (of course, those commands can be easily generated by using ORACLEs dictionary, but it is annoying). And how should those one-code-table look like? What additional columns are needed? „Beside the code at least its meaning, like F for female“. And what about the problem, having different additional information per business code like geo-information for cities and airport-service-hours and runway-length for airport-codes. How should a one-table-solves-it-all look alike?
But if you need an only check whether a value is valid or not regarding your business it is possible to introduce a key-value pair by introducing some kind of category like a static_data table:

And then introduce new domains as

Column names for primary and foreign keys
Primary key columns
First, a primary key is not intended to change over lifetime. It is not a business key, which might be updated or change its appearance due to new business rules (like car signs, ID-card-numbers or invoice numbers could).
Conclusion is, a primary key usually gets created automatically (by e.g. using ORACLEs sequences). There might be reasons to have a primary key to be unique of more than one table. This can be done as well with help of a single sequence for more than one table.
From my experience, a primary key should always be a single column and never be a combination of columns. If you need a combination of columns to be unique, you use unique keys (based on e.g. two foreign keys, which themselve reference a primary key each).
Don’t consider a primary key column to be called ID_PK for all tables, remember the goal to put semantic in column_names to go for automation of standards as much as possible.
Since there is a 1:1 relation between a primary key and its table (there can only be one primary key per table), the idea is to relate both table_name and primary_key column and at least partially derive the primary key column_name from the table_name. Remember our table MAR_CUS_CUSTOMER? Why not call the pk-column MAR_CUS_PK? Well, we have an additional table MAR_CUS_CONTACT, which then has the same pk-column_name which will not be very self-explainable. So you need any unique abbreviation from the last part of the table, in my case i decide to introduce a shourtcut CUS for customer and CON for contact. My primary key columns per table are called MAR_CUS_CUS and MAR_CUS_CON (they are not, since they have no domain yet. keep on reading). Keep in mind, that there will be no collisions in pk-column naming across our table-naming-hierarchy: If you have a table PRD_PRD_CONSTRUCTION and go for a shortcut CON again, your pk-column name is derived as PRD_PRD_CON.
Of course you need a unique shortcut within tables belonging to the same category/component. This 3-digit-shortcut for the last part of my table name, is this relevant in future? Yes, let’s have a closer look, again it is about semantic and automation:
First, let’s consider those columns to be of an own domain, we do not reference a domain for generating check constraints or reference a business code. We only want to generate unique values. Our domain for pk-columns is PK, so my columns are called MAR_CUS_CUS_PK and MAR_CUS_CON_PK.
I would like to use ORACLEs mechanismn to generate PK-values automatically for those columns. Nowadays there is a feature implemented which relies on system-generated sequences. But if you want to be of full control over system generated key-values you should decide to go for the old-fashioned way:
We introduce sequences to generate pk-values for the above mentioned column. To achieve this, we need to assign/generate a sequence and declare a trigger to assign a new sequence-value for a given row (or even forbid to assign a new pk-value to an already stored row). Guess where we store the information needed for those automatisms? In our domain-table! We have a domain called PK and we can assign a sequence to be used for primary key generation per column.

Sidenote: We invented a domain called PK to reflect a single datatype to be used for primary keys. If your primary key values are based on different datatypes you should rethink your overall design.
It is no good idea to introduce domains for FK (foreign keys) or UK (unique keys). The domain FK needs always to be the same to the PK domain, so it is useless to introduce this additional domain. Wait! Foreign keys can refer to unique keys as well! Again, the FK datatype relies on the referenced UK datatype. Why not introduce a UK domain? Because uniqueness can not only be applied to one single datatype. A domain has a single datatype, so you would need to introduce a UK-like domain for whatever datatype you want uniqueness on. Bad idea…
Time for full flexibility because we cared about naming conventions? We do not really need a static assignment via a domain. Further more, this maybe would lead to performance issues, if this single sequence is referenced intense
We have three levels of systemgenerated pks. First level would be on a per table basis. For MAR_CUS_CUS_PK a sequence MAR_CUS_CUS is generated and a trigger is generated to provide a systemvalue for the pk-column.
Second level would be on a per category basis: You want to share a systemgenerated pk-value among a set of tables. Therefore we use the two-level-standard our tables belong to: a sequence MAR_CUS will be generated and a set of triggers will be generated to provide a system generated value from ONE sequence of A SET of tables.
Your third level of pk-value-assignment would be one sequence for a whole component like MAR, PRD and so on.
The limit of this automatism is, you can go only for one technique to derive the right sequence and the set of tables where the sequence value should be applied to. This is the only possibility to avoid naming collisions.
But luckily we introduced domains to overcome this limitation:
You want for all tables of component PRD and category PRD (e.g. PRD_PRD_PRODUCT, PRD_PRD_ITEM and so on) a unique sequence value per table you use domain PK for those primary key columns. Assign a level 1 derivment for pk-values (accordingly sequence PRD_PRD_PRODUCT_SEQ, PRD_PRD_ITEM_SEQ and so on will be generated).
But for component MAR you want one single sequence to share its values among the pk-columns of all tables belonging to MAR. This is where you introduce a new domain PK3 for all pk_column_names of tables belonging to MAR. In you domain definition you define a level 3 derivment for your domain PK3 (this will generate a sequence MAR_SEQ).

You can even mix it up between different subcategories of the same component: If you need a dedicated sequence for all tables MAR_CUS_* you name those primary key column *_PK2 and introduce a domain with seq_level 2 (this will generate a sequence called MAR_CUS_SEQ). But you need to „stay“ in your hierarchie. E.g. you cannot share a „unique“ primary key value among tables from different categories/components, this will lead to naming collisions or more than one option to choose from, which our automatism can not decide.
We can even implement checking and quality assurance scripts to check, that there is no misconfiguration in your assigned primary key domains and hierarchy of table names.
Beside the primary key column there might be additional columns which are feeded from sequence values like a column to track a certain order of rows or else. Use the same technique and define a domain for those columns to contain a systemgenerated number. To make it work you only need to invest in thoughts how a unique sequence_name could be derived without colliding with existing ones. Once the sequence is known it is easy to generate a trigger to populate those columns belonging to the domain with the sequence value.
Short notice: You could achieve this level of automation with help of primary key constraint name conventions, too. But it’s about semantic. The earlier you adress semantic the easier it is 1. to follow the rules and 2. to gather information (here: without querying for certain constraint names). Constraint names are different to primary key column names: they come e.g. into play when it is about constraint violation. This is, where we want to introduce additional conventions for handling error message. So stay curious…
Example for automatisms on using primary key naming conventions with help of domains:
Foreign key columns
When we introduced domains and business codes we already discussed that you are not enforced to introduce referential integrity for simple domains like yesno-domains or gender-domains.
Foreign keys are used to ensure an overall integrity regarding the existance of referenced records to be prerequisite for other records to exist. E.g. an invoice may not exist when the customer is not known. An offer can not exist, if the product or service I like to offer does not exist.
Technically spoken, a foreign key is used to reference other tables (or even the same table itself), whereas a business code or value domain does not necessarily need a corresponding referenced table.
From the automation point of view foreign key naming conventions are not as important as for other objects around, because the name of a foreign key column does need no automations to be defined on. If we need automation we will concentrate on the foreign key constraint name, but not the column name.
Let’s have a look on conventions I read of:
„Name the column with a prefix FK, followed by the source table and target table“.
I have two problems with this naming convention: First, why should I name the source table in the column name? It does not make sense, since I am always able to get the table_name the column belongs to from ORACLEs mighty dictionary. Even if you would follow this convention: column names will simply become too long, if we use our naming hierarchy for tables and primary key columns. Second what, if I have more than one foreign key column referencing the same PK of another table? OK, this does not fullfil our needs, away with it.
Consider the shortcut FK first. Since we reference a primary key with its domain PK (which is coded at the end of the column) it would be stupid to loose this information when we name foreign key columns. The foreign key needs to have the same domain as the referenced primary key, this is the key concept of referential integrity. Two learnings: Use the same domain in the column name as the primary key column does, second (derived from the first): Do not put a shortcut FK at the end of a foreign key column name.
With our naming conventions for primary key columns it is quite easy to implement a standard:
Use FK as a prefix for the foreign key column followed by the name of the referenced primary key column, that’s it.
Wait! What if I have more than one foreign key column referencing the same primary key as a reference to a „creating colleague, a working colleague and a reviewing colleague“ in the meaning of a jira-ticket for instance? Above rule would not fit.
Then add a meaningful abbreviation between(!) prefix FK and the referenced primary key column.
Example: Your colleagues table is called HR_EMP_employees, the primary key column could be named HR_EMP_EMP_PK, so my foreign key columns are named FK_creating_HR_EMP_EMP_PK, FK_working_HR_EMP_EMP_PK and FK_reviewing_HR_EMP_EMP_PK. Done.
Since we do not use these conventions to realize automation activities, it is not really needed to obey this convention but I highly recommend to use a prefix to visualize, that there is a contraint on that column and to keep the postfix PK to reference the used domain.
Wait! A foreign key can be defined on a unique column as well. Oh, yes! But you would certainly have chosen a different domain name than PK for that unique column, so call your unique key column with that domain of the target column as a postfix. Done.
Wait! There may be a combination of two or more foreign key columns which reference one primary key which is a combined set of columns as well (this goes for unique constraints as well). Concatenated primary key columns should be omitted as already told in the discussion regarding primary key columns. But this can’t be stated for unique constraints and their columns. Uniquess across more than column is business as usual. Well, there will be no technical problem to apply the same rule as for a single unique column, neither in the primary table nor in the referencing. But as you cleary see, our naming conventions come to an end to reflect those semantic circumstances only with naming conventions for columns. At this point you need to ask the ORACLE dictionary for further information.
Constraint names
Regarding constraints, naming conventions are important. If you violate constraints, ORACLE will always use the constraint name which is violated, never the column name(s) the constraint relies on. So if you want to setup an overall error handling to be the same on your whole application you should spend time into thinking about constraint names. And again, put semantic into your constraint names to be as informational as possible in case of constraint violation or even built up a method to return „business-like“ error-messages and less technical error information where an application-user (or even a frontend developer!) has no idea how to deal with it. We will introduce an error framework for „business-like“ error-messages later. But this chapter is prerequisite for such an automation.
Let’s first have a look on our environment:
ORACLE says, there are nine constraint_types (https://docs.oracle.com/en/database/oracle/oracle-database/19/refrn/ALL_CONSTRAINTS.html#GUID-9C96DA92-CFE0-4A3F-9061-C5ED17B43EFE)
C– Check constraint on a tableP– Primary keyU– Unique keyR– Referential integrityV– With check option, on a viewO– With read only, on a viewH– Hash expressionF– Constraint that involves a REF columnS– Supplemental logging
But this needs some explanation:
The first four are the most relevant to look for conventions since you want to automate or you want to report about quality and completeness of your database scheme. Constraint types V and O are only relevant for views (honestly, I do not even know, if you are able to name them yourselve). We will cover those constraints in chapter views.
Type S are constraints for both Change Data Capture and even AQ. The idea is to include unchanged data in redo logfiles to make it easier to apply those changes in a target destination. This will not be covered by these architecure thoughts.
Type F is only relevant if you use ORACLEs object-oriented-alike approach to go for inheritance and object-related tables. This topic will not be covered by these architecture thoughts and has to be placed to thoughts around PL/SQL and SQL.
Type H: I have no idea, please give me a heads-up to help. This topic will not be covered by these architecture thoughts.
Let’s first have a look on the missing: a NOT NULL constraint.
NOT NULL constraint
If you add a NOT NULL constraint, it in fact becomes a CHECK constraint (type C). It would be the same as a CHECK constraint stating „<column> IS NOT NULL“ with the difference, that the need of a NOT NULL won’t show up in a DESCRIBE command.
SQL> alter table t add constraint my_named_not_null check ( x is not null ); Table altered. SQL> desc t Name Null? Type ----------------- ----- -------- my_named_not_null NUMBER(1)
Beside this is a manually „constructed“ not null constraint, it would lead to a different error message (violating a check constraint) than having an „original“ NOT NULL constraint. If you work with NOT NULL assignments per each column, keep in mind to use the possibility to name them. If you don’t, the constraint will get a system generated name. You will still be able to see them in the view user_constraints where they will show up as a check constraint.
Sadly is it not possible to choose a constraint name when assigning a NOT NULL to a column while creating the table. You have to do it afterwards (as for CHECK constraints) by
SQL> alter table t modify x constraint my_named_not_null not null; Table altered. SQL> desc t Name Null? Type ----------------------------------------- -------- ---------------------------- X NOT NULL NUMBER(38)
If you do not name NOT NULL constraints explicitely, this will have no impact on any reporting or automation mechanisms, since you can gain this information from ORACLEs dictionary. But it may have impact, if you want to compare your application throughout different databases or schemes, because ORACLE will name these unnamed NOT NULL constraints with a system generated name, which will surely differ. Again, to resolve those differences it needs only a closer look to the dictionary, so it is no no-go to work with system generated NOT NULL constraint names.
But you surely do not want to „simulate“ a NOT NULL constraint by adding a CHECK Constraint which does the same. Your SQLPlus command DESCRIBE won’t show up those NOT NULL columns.
Whenever you go to name those NOT NULL contraints on your own, consider to give them the column_name followed by a NN postfix (or prefix). Even if such a column could be used in different tables it is a breeze to retrieve the table, the column belongs to.
Check Constraint
As of now, we know that CHECK Constraints can be automatically created based on the domain, a column is based on. But there may be additionally needs to define CHECK Constraints. Either due a needed combination of different column values or an even stronger check than the domain itself defines.
Have a look on this case: You have a column execution_on_WDAY, where WDAY is your domain from 1-7 for a weekday. But buiness schedules argue, that execution times are only on working days. For sure, you can easily define an own domain for working days only.
As business is alike, they now state, that execution times can be on every day of a week, but only on weekend, if it is an emergency call.
You have two domains. On the one hand a column execution_on_WDAY belonging to domain WDAY (1-7) and another column emergency_call_FLAG belonging to domain FLAG (Y or N). For both columns a CHECK constraint can automatically be deployed. But the combination of both is impossible with our domain concept.
This is where additional CHECK-Constraints come into play. You need a CHECK constraint like (emergency_call_FLAG=’Y‘ and execution_on_WDAY in (6,7)). This means, to be active on the weekend it needs to be an emergeny. On the other hand, on a working day there is no emergeny action possible. Due to the many possibilites of defining additional CHECK constraints I do not see any chance to check, that either of these arguments can become true at all (maybe the domain FLAG only allows values ‚X‘ and null). So this is responsibility of a developer.
In easy cases it might be even possible to generate test cases automatically (so for FLAG which is VARCHAR2(1) and WDAY which is NUMBER(1) it would be possible to generate all test combinations to prove, that there will be cases which lead to TRUE or FALSE for all combinations of values, but this soon become not to handle anymore for complex conditions with „big“ datatypes). And if a domain value range changes, it might be interesting to see, if there is any impact on CHECK constraints which rely on those domains.
Please do not think this is a limitation due to the domain concept, the same problem is valid if you do not introduce domains. The benefit is, that domains help us to visualize CHECK Constraints which rely on certain domains and then further investigate the impact of changes to domains. If you do not go for domains you still can investigate impact by querying the dictionary: Search in all check constraint conditions for column_names which are columns of the table, the check condition is based on.
The conclusion is: You need CHECK constraint names which can be generated automatically based on the domain, the column relies on PLUS additional CHECK constraint names which show up the domains, the condition is based on.
Primary Key Constraint
While we thought about naming conventions for a primary key column, we now think about the name of a primary key constraint. The good news: A primary key constraint does only exist once per table. So you could use e.g. the name of the table and add a _pk postfix to name the primary key constraint. When does this decision becomes visible to a user or a developer? Well, ORACLE tells you about the primary key constraint name, when you violate the constraint. And a constraint violation for a primary key constraint is only possible for INSERT/UPDATE operations, when the (new) primary key value is already used for an existing row in the table.
If you do not have a framework installed which generates a user-friendly error message (like „this identifier for a customer is already in use“ or so), the constraint name will be part of the error message which is presented to the user and therefore may give an intruder/hacker additional information about the table name, if you use a constraint name derived from the table name with an added postfix _pk. May be not a good idea to offer information about your inner architecture.
I experienced it to be very helpful to use a primary key constraint name as the column which forms the primary key is named. At least, if your primary keys are setup as a single column generic value as i suggested before. The constraint name will hide additional information to conclude to the table name where this constraint_name is used. If your constraint is named like the column is named, it is really easy to ensure, that 1. every primary key column has a constraint on it and 2. derive the underlying table in case a constraint violation occurs.
When we forecast a framework to translate „technical“ error messages (like mar_cus_con_pk is violated) to more readable error message, which can be communicated to the end-user (like „this contact information already exists“), it is easy to map a primary key column to a certain error message if the primary key constraint name is the same as the primary key column. But this will be introduced in <link>.
Foreign Key Constraint
Foreign key constraint names are pretty different to primary key constraint names due to several facts:
- There can be more than one foreign key constraint on a table
- Many foreign key constraint may reference the same primary key constraint
- A foreign key constraint can not only reference primary keys but unique keys as well
- In case of errors, ORACLE presents the same foreign key violation in two different ways, depending on whether a parent key was not found or a parent can not be deleted, because there are child records existing
To derive the foreign key constraint name from the foreign key column as we suggested to do for primary key constraint names is too short: there may be more foreign keys referencing the same primary key (e.g. two different tables referencing the same „master“ table), which would lead to duplicate constraint names in different contexts.
Let’s recap the naming conventions for foreign key column names:
„Wait! What if I have more than one foreign key column referencing the same primary key as a reference to a „creating colleague, a working colleague and a reviewing colleague“ in the meaning of a jira-ticket for instance? Above rule would not fit.
Then add a meaningful abbreviation between(!) prefix FK and the referenced primary key column.
Example: Your colleagues table is called HR_EMP_employees, the primary key column could be named HR_EMP_EMP_PK, so my foreign key columns are named FK_creating_HR_EMP_EMP_PK, FK_working_HR_EMP_EMP_PK and FK_reviewing_HR_EMP_EMP_PK. Done.“
There may be additional columns FK_HR_EMP_EMP_PK from several tables referencing the same primary key.
To be unique with foreign key constraint names we need to code the source table within the foreign key constraint name to avoid naming conflicts. The source table can be identified with the overall unique primary key column name, right? Let’s use it!
Consider the master table HR_EMP_EMPLOYEES with its primary key column HR_EMP_EMP_PK. The primary key constraint name is named as the primary key column is. Easy.
Now we have a table HR_DEP_DEPARTMENT which needs a department leader who is an employee. So we need a foreign key to HR_EMP_EMPLOYEES. The column would be called FK_HR_EMP_EMP_PK (note, that this column can occur in more than one table!).
My table HR_DEP_DEPARTMENT has a primary key column (the same as the constraint name) HR_DEP_DEP_PK. To code the source of the foreign key into the constraint name we easily call the constraint FK_HR_DEP_DEP(we omit the _PK since its domain is not needed)_HR_EMP_EMP_PK (here the _PK is needed to reflect, that we reference a primary key and not a unique key!).
FK_HR_DEP_DEP_HR_EMP_EMP_PK would be the constraint name and reflects the source table and the target primary key table, the constraint is evaluated against.
If you need to introduce two foreign keys on HR_EMP_EMP (consider a department leader and its deputy) you already named your columns FK_leader_HR_EMP_EMP_PK and FK_deputy_HR_EMP_EMP_PK. The resulting foreign key constraint names would be FK_HR_DEP_DEP_LEADER_HR_EMP_EMP_PK and FK_HR_DEP_DEP_DEPUTY_HR_EMP_EMP_PK.
You may even argue to omit the postfix _PK, since HR_EMP_EMP is already unique, but keep in mind the unique columns a foreign key may reference as well!
<unique key columns referenced by FKs!>
Now you may hesitate to convince your developers to go with such naming conventions on foreign key constraints. It looks much to difficult to figure out the right constraint name as is FK_HR_DEP_DEP_LEADER_HR_EMP_EMP_PK.
These naming rules are not intended to be derived by a developer manually but to be generated automatically! Everything is done to let ORACLE produce the correct constraint names and even generate the foreign key constraints.
Your developers just need to care about column naming conventions, everything else will be done by our framework we are going to develop. Let’s have a look, where we are:
<image showing table definition (deriving datatype from domain table) and automatically generated sequences, triggers, check constraints, primary key constraints and foreign key constraints>
Unique Key Constraint
Unique keys and its constraint naming is somewhat difficult: We can not use a postfix to indicate a used domain since the uniqueness can be applied to any domain in different contextes. So no chance to name a column with postfix _UK. And uniqueness maybe needs to be enforced throughout a combination of columns, which is different to primary keys where we stated to have a single column to be primary key.
We did not mention any conventions for a single column or a set of columns to be part of a uniqueness. So unique constraints can not be derived from column names, the unique constraint has to be defined by the developer. The constraint name should at least reflect, that the constraint deals with uniqueness, so introduce an abbreviation UK. Since it is nearly impossible to introduce a naming convention which is based on the column_names (or domains) being part of the unique constraint I suggest to name those constraints like the primary key constraint is named with the postfix _UK instead of _PK. If you have more than one unique constraint on a table, consider to add a counting number to the end of the constraint name like mar_cus_cus_uk_001.
View names
It is difficult to separate naming conventions for views from a good architectural view design. We used naming conventions for tables, which can be used to split components/modules and so on, This is, what I would call a horizontal split to find out which table names are intended to interact (e.g. via foreign keys) or must elsewhat being categorized (like business responsibility for Marketing (this is why we introduced MAR as a prefix)).
We should introduce view naming conventions not only to visualize the source the view is based on but use naming conventions to split our application vertically in the meaning of „who is intended to use the view and how“.
First of all, a view name should reflect the object type VIEW. I am not willing to check in the dictionary what type of object I am dealing with. So consider to introduce a Pre/Postfix V. I prefer a postfix variant, so a view, which is based on mar_cus_customer would be called mar_cus_customer_v. As long as it is a simple view. What is simple: The view is based on only one base table and does not hide a join. Second, the view populates the columns as they are in the base table (so you don’t use aliases, derived attributes or else functions, case commands and so on.
Why?
I mentioned, that we should use views for horizontal separation of access layers. So this very first idea of view naming with the said restrictions allows to use several automatisms in deployment.
Think of a base table where you want to add additional columns for „last_change_at“ and „last_change_from“ for security and revision reasons. You would never allow access to such a table to the frontend-user (or GUI-application). You would introduce a view to show only the relevant columns (e.g. all but the last_change-columns).
Maybe an automatism generates a base table trigger to feed the last_changed-columns with values, the GUI is not allowed to see those additional tracking columns and they are therefore excluded in the view definition. Well, this is done on the base table, not on the view? Yes, but think of additional validations (like business-like privileges, which depend on further data and not on privileges on certain objects as ORACLE is based on). You would now introduce certainly instead-of-triggers. These triggers can be generated automatically, if the view name reflects, that the view is a 1:1-relation to the base table and includes all columns (except the last_change-columns) which are mapped identically to the base table. These IOTs (Instead-Of-Trigger) could be generated to be a sceleton for additional logic to be implemented (such as validate additional access/modify privileges). Or you use those IOTs to be your „hooks“ to call additional package-procedures where your business logic and business validation resides. Benefit of the latter is, that your triggers are generated automatically and in case of errors in production you can be pretty sure that the error has to be solved in called packages and not in triggers which are generic.
This is why a „standard“ view should be based on the table in a 1:1 relation without additional formulas, joins or else.
There may be additional views (and therefore naming conventions) like: the view is based on more than one table, or you need different additional validations for different manipulations (e.g. you need views for GUI interaction, but DML-Jobs via batch-jobs underly different rules).
Therefore you might name view with a postfix _VGUI and _VBATCH or _V1 and _V2 to assign those views to different usages.
And what about views which hide a join on more than one table, a DISTINCT, a GROUP BY or else? With my experience I would never present a view based on more than one table for use in data manipulation. While the introduction of IOTs is (yet) just a suggestion, you will certainly need IOTs on views based on multiple tables to control the needed actions if someone tries to change data via the view. Don’t, don’t do it.
If you need views which are not intended to be used for DML, 1. set them READ-ONLY, and 2. you need additional naming conventions: Name those views beside the _V with „LIST“ or „OVERVIEW“ to signal, that those views are not intended to be used for DML.
To recap: Name Views with a pre- or postfix. Set views read-only, if they are not intended to be used for DML. Use additional pre/postfixes, if the base table needs to propagated different from certain users/jobs (like GUI vs. BATCH).
Keep in mind, that those naming conventions can be used to generate additional objects (like here: triggers or DML-privileges to database users).
We will have a more detailed look on views in <link>
Side note: To benefit from automation, we introduced domains. They make it possible to automate either check-constraints or base-table-triggers to validate data which is going to be stored in tables. But you should not implement business rules in base table triggers (like column1 must be value1 and column2 must be value2). This is not the intention of domains. You can put this logic into check constraints but it should be implemented in triggers based on views (IOTs), because: in triggers you can check the value before and after the DML (which is not possible in CHECK constraints) and you can use a IOT as a hook to call additional procedures which allows to implement all your logic in one object type: Package/Procedures/Functions. This makes debugging pretty easy, since you don’t need to investigate a set of object types. And, if the business rule is implemented per view, you can easily implement differences (again: GUI-users vs. BATCH-processes) in business validation.
Trigger names
I left my last project with much automations implemented. One of those automation benefits was the automated generation of triggers. The automation took place for generating base table triggers to store additional information to each row of a table (last_change date and changing user as creation date with creation user, and automated generation of a primary key value and a flag to implement optimistic locking for GUI interaction). Further more trigger were generated for logging a history on certain columns of a table. This was realized via a special named unique constraint (which indicated the business key of each row) which existance led to the generation of a trigger to save each modification of a row to a history table.
If you want to reach automated trigger generation you surely need naming conventions. Even if not, you need them to apply quality checking on your database model and to make it possible to evaluate your implementation easily.
If an unhandled exception occurs, the trigger name is part of the error message. Although you might not present the failed trigger name to GUI nor present a more detailed error message on base of a failed trigger (if you consider a trigger to fail without specific error handling or messaging, this should not lead to expose a trigger name to GUI).
Although all individual configuration of a trigger is part on the ORACLE data dictionary and can easily be retrieved, you should again put as much semantic as possible into trigger names.
Let’s start at the end of the name: Put a _TRG at the end of a trigger name to visualize the type of object in case you get e.g. invalid objects. This makes it easy to find out, that it is not a package or else but a trigger which is invalid.
Triggers come in different flavours: as a statement trigger or a row trigger. And you can even define, when the trigger should „fire“: before or after the DML-statement or even instead of the statement (in case of views). To distinguish those triggers you should add R or S to specify a row or statement trigger. For the triggering order you use B(before), A(after) or I(instead). Trigger can be executed only for certain DML-statements which are executed on the table/view, e.g. only for INSERT-operations. So again use the DML-statements the trigger reacts on as I(Insert), U(Update) or D(Delete).
I know, there are compound trigger and even „follows“ clauses to define an order in case of more than one trigger being fired. If you use those trigger techniques, adapt the naming conventions accordingly.
If you benefit from automated trigger generation, consider to reflect the automated generation in the trigger name (e.g. with a postfix AUTO), but even better: if you automate trigger creation those trigger will have a certain task to fullfil, so use an abbreviation for automated triggers describing the need for the trigger. E.g. if you use automated trigger generation for logging activities, consider to use LOG in the trigger name. On the other hand, this impacts, that no developer should create manually triggers in this special naming domain to be sure, that those manually created triggers are not accidently dropped because you thought to regenerate them automatically.
There can be more than one trigger per table, per event, per row or statement trigger and per DML-statement. You will get into trouble, if your naming conventions says TRG_<primary key constraint>_B(efore)|A(fter)|I(nstead)_<DML-List like IU or IUD>. Consider two triggers on the same table firing for the same event on the same time like one Trigger for logging activities in case of an insert an another trigger for checking permissions in case of an insert. With the naming convention above this wil not be possible, both triggers would be named the same. Don’t think to use a counting number or something like this! Consider to use additional infos regarding the task of the trigger. E.g. one trigger has the postfix LOG which describes its task to log INSERT activities and name the other trigger elsewhat, depending on if this trigger is generated manually or automatic. In case you manage to automate trigger generation for privilege checking you certainly should use another abbreviation e.g. PRV. To make it easy to distinguish manually created from automatically created trigger you can also consider to use MAN or AUT. This would lead to easier identification of valuable trigger code versus automated code which can easliy be reconstructed.
An automatically created trigger for Logging activities would be named
TRG_AUT_MAR_CUS_CUS_B_IUD_LOG
An automatically created trigger for checking additional privileges would be named
TRG_AUT_MAR_CUS_CUS_B_IUD_PRV
A manually created trigger uses MAN instead of AUT, the last topic it deals with could be omitted like
TRG_MAN_MAR_CUS_CUS_B_D
But maybe it is better to put describing context to the trigger name, so in case a customer is deleted, this trigger should send mail to marketing lead:
TRG_MAN_MAR_CUS_CUS_B_D_INF(orm_lead)
Even if you have automated triggers in a field of INF, those triggers can easily be separated via their MAN or AUT in the name.
Sequence names
Sequence are a preferred way to be used for primary key generation. So sequence names are in the field of your primary key column and primary key constraint naming rules. Our aim is to easily see which sequence is used for which primary key column(s) or even to generate triggers to propagate the primary key column with the correct sequence value.
Remember our thoughts about naming primary key columns? The easiest way is to use our domain table, where we defined the domain _PK to be of number(38) and now we introduce an additional column SEQ_NAME to put the sequence name in we want to be used to populate all primary key columns of all tables. Hm, this may lead to a performance bottleneck if we use one sequence to populate all tables.
OK, We could use the primary key column name (which is based on a one-or-two level hierarchy like MAR_CUS_CUS and MAR_CUS_CON) to derive the sequence names from (in this case SEQ_MAR_CUS_CUS and SEQ_MAR_CUS_CON). This means a sequence per table and is the other extreme to the first idea, where all primary key columns use the same sequence.
Both ideas are not very flexible.
Another idea: introduce additional domains PK2 and PK3 to assign different sequences to. This means, by naming a primary key column you assign the to be used sequence. It is more flexible but seems somewhat „unorganized“, since you could assign the same sequence to tables from PROD and MAR, which may be no good idea.
OK, let’s go for better organisation and use the hierarchy we introduced to table names and therefore to primary key column names:
In our domain table for domain PK we add a column SEQ_LEVEL instead of SEQ_NAME. This level reflects, which sequence is to be used for different tables from different components/modules.
Consider a SEQ_LEVEL=1 for the domain PK: This means, the to be used sequence name is derived from the most upper hierarchy: In case of MAR_CUS_CUS, MAR_CUS_CON and MAR_ART_ART, the to be used sequence is MAR.
If you use SEQ_LEVEL=2 for the domain PK, the first two levels are used to derive the sequence for primary key values: A sequence MAR_CUS and a sequence MAR_ART. A SEQ_LEVEL=3 means a per table sequence as discussed above.
You could combine this technique with more than one PK domain. E.g. use PK for a SEQ_LEVEL=1 and introduce a PK2 domain with SEQ_LEVEL=2. This leads to:
MAR_CUS_CUS_PK uses a sequence called MAR, while MAR_CUS_CON_PK2 uses a sequence MAR_CUS.
You see, you can implement and combine different techniques to a assign the correct sequence to a primary key column to get the values from and you have quite good flexibility with domain information and hierarchy assignment.
In my last project we did not need this flexibility and went for a single sequence per module (hierarchy 1, so MAR_CUS_CUS_PK and MAR_ART_ART_PK both used a sequence MAR) and we did not assign a SEQ_LEVEL to our domain table. Though to be more flexible for future changes it would not be more effort to introduce the SEQ_LEVEL.
If you consider to use different PK-domains to assign the correct sequence, this may lead to bad organisation. Think of a domain PK which is assigned to sequence MAR and a domain PK2 which is assigned to sequence PRD. This may accidently lead to a column MAR_CUS_CUS_PK2 which is feeded by sequence PRD. This is no good organisation!
If you want to assign different sequences on a per hierarchy basis, consider to introduce an additional naming convention for your primary key columns:
MAR_CUS_CON_1_PK and MAR_CUS_CUS_2_PK. This „level“ 1 or 2 now means that for 1 a sequence MAR is used and for 2 a sequence MAR_CUS is used. This is how you achieve flexibility in the use of sequences but keep it organized well. It would be no more possible to use a PRD sequence accidently for a MAR table, since you no more use different domains.
Exception names
This heading may be misunderstood: In the world of PL/SQL we always work with exceptions, which may be handled by the called unit itself or be raised to the caller. In case an exception is not handled within the calling hierarchy, the exception will be presented to GUI. This exception may be an ORACLE-exception (such as „no data found“) or an exception, which has been defined within PL/SQL and therefore is presented to the caller as „user-defined exception“.
Let’s have a look from the top: I want to deliver error messages as be precise as possible to GUI. And I don’t want to present technical error messages (like „parent key does not exist“ or „unique key XYZ violated“) but business like messages, where the consumer (the GUI) can deal with (either by forwarding the message like „please use M, F or D as a gender“ or by handling the error itself e.g. by redirecting to a page „create customer“ in case a given customer does not exist).
So, to signal ecxeption, which can not be dealt with in the inner ORACLE logic, we need somewhat like riase_application_error, which is provided by ORACLE to deal with user-defined exceptions. The problem is: it is limited to 1000 error codes, which might be not enough for our application. And where to map those error codes to? How to be sure, that every (technical) exception is mapped to a (business) error message?
All those exceptions within the SQL-world (means: without looking for PL/SQL error handling) are derived from constraints which are violated. So you should consider to use constraint names to derive your business error messages from. Map your primary key constraint MAR_CUS_CON_PK (which is from marketing module regarding customer component and my be a contact primary key. You see how helpful our naming conventions become to get precise information!) to are more business like error message like „This contact information for a customer of marketing already exists“.
Be aware that in case of violated foreign key constraints we need to handle two „directions“ of errors: Either a to be deletet row can not be deleted because there a child records existing or a foreign key value can not be inserted because the master (parent) record does not exist. So to handle foreign key violations we not only need the constraint name but its semantic (which ORACLE surely tells us!).
So for now, we know we can setup an own error handling framework where we derive all business error messages from the violated constraint names, and therefore can even prove, that every constraint violation leads to a business-like message (by comparing the constraint names to our mapping table to be sure, all constraints are adressed).
Heads up to PL/SQL error handling: there is this mighty declaration „EXCEPTION“ and a directive „EXCEPTION WHEN OTHERS“ to be used by PL/SQL-programmers. If you think of calling hierarchies the caller (which is the GUI in the end) will get a „user-defined“ exception, if it is not handled by the called procedures itself. A calling procedure can only deal with a „user-defined“ exception when it can reference this exception, which again is only possible, if this exception is made referencable. This can only be done by using packages where the exception can be part of the package specification. So this is the first reason for the recommendation to use packages only in your framework and not deal with stand-alone-procedures.
As of now, we do not need any naming conventions for PL/SQL exceptions (as we did not focus on naming variables, constants, parameters and so on), since we assume, that those errors are handled by PL/SQL itself. If not, GUI will surely get an error „user-defined“ exception, which is not what we want. We more need a concept to save the calling hierarchy of an error and to implement logging features, but this is apart from naming conventions and will be discussed <here>.
Synonym names
Within this discussion we assume a single GUI-user to be used to connect to an ORACLE database, this is why I do not discuss public synonyms. If your application uses dedicated ORACLE-users per GUI-user, there may be a need to have a look on public synonyms.
I think of an architecture, where there is only one ORACLE-user, the application is allowed to connect to.
This said, synonyms come into play, if you consider this user to access objects of schemes which are not its own.
Don’t spend a thought on synonyms if you can assure that all objects, the application needs access to is in your application-users scheme. If this can’t be assured, go on reading:
A synonym is basically an alternate naming of an object which resides somewhere in the database (normally in different schemes, but even in different databases when it is used in combination with database links and views). The idea of synonyms is to implement „Ortstransparenz“ (maybe translated with location transparency). As long as you deal with objets in your own scheme, there is no need to (and it would be even contra-productive) to use scheme-names to access objects in the database. But if you need access to objects which reside somewhere else, synonyms come into play: your code should neverever use hard-coded scheme-names, in case you need access to other schemes or databases use synonyms! This is what they are made for!
Example given: my last project dealt with to schemes hardly interacting with each other. So, every developer used the scheme name in its code to access the object outside its own scheme. Let‘ call these schemes A and B. So the developer in scheme A accessed the objects in scheme B by coding „select * from B.customer“ and vice versa. This was not done in purpose, those developers assumed that there will always be those two schemes in any environment. But there was not! Although for production, these schemes will last all our lifes in production, we had a problem to deploy the application in a different environment: We did not had another database to create the same schemes but enough space to deploy to different schemes in the same database. How easy this would have been, if we easily „relink“ the synonyms from scheme A (which is the new A1) to B1 and from scheme B (which is the new B1) to A1.
Result:
- Use synonyms to be transparent of location (and only for location!)
- Do not use synonyms for objects in your own scheme (this is what views are made for).
My suggestion: Name the synonym as the target is named with an additional pre or postfix to reference the location of the object (this location can be your scheme A or B as mentioned before, but it should somewhat abstract from a scheme. Like ANALYST and BUSINESS). Keep in mind, that additional scripts may need this convention to e.g. grant access to those synonyms in different schemes.
Package, procedure and function names
When it comes to PL/SQL and its objects they read or even manipulate, naming conventions may become difficult. If course we need a prefix like PCK for package, PRO for procedure and FUN for a function. Since I suggest to only use packges to let someone interact with the database, there only will be PCK as a prefix.
How can we put semantic into package names? Packages do not only access one but many objects and they read or manipulate data of different objects. How can we even a assign a package to be part of a component or module, if those packages access objects from different sources?
Second, the „bigger“ our packages become (the more logic is implemented in a package) the more we can expect conflicts, if more than one developer is working on the same source.
If my package accesses objects from different moduls/components I derive the name from the module/component where the logic resides on. E.g. I decide to name my package with the component MAR_CUS (marketing, customer) even if I know that my package is going to access components/modules from PRD_PRD (production, product). Part of my considerations is: Can Production/Product work, even if I can not deliver my changes to component MAR_CUS to production?
Keep in mind: Your packages are not intended to deliver data. This is done by views. So consider your packages only to be used for data manipulation. As this said, your packages should be assigned to the component where the manipulation is initiated from. E.g. If marketing (MAR) in case of customers (CUS) is needed to manipulate production data (PRD_PRD) you should consider this package to be part of marketing and not of production.
So here we go: name your packages with a prefix like PCK followed by the component where the data manipulation is initiated from (like PCK_MAR_CUS).
Use these prefixes to put semantic in your package names. Of course you could easily query all_dependencies. And this query should always show, that a „calling“ package depends on a „called“ package without being depedendant on an object which is not part of the same component/module.
Summary
You may still not be convinced to introduce a „hardliner“ sight on naming conventions.
So I owe you a graphic showing your datamodel based on the upper said and all automations which can be applied on naming conventions, which will be further discussed in #link
#placeholder graphic datamodel lean
#placeholder graphic datamodel enhanced
Before we consider to go to automation, let’s first have a look on #good scripting, which will be the base on perfect deployment without any issues